Lung-Hao Lee, Chen-Ya Chiou and Tzu-Mi Lin.
In Proceedings of the 18th International Workshop on Semantic Evaluation (SemEval-2024), pages 1455–1462.
Abstract
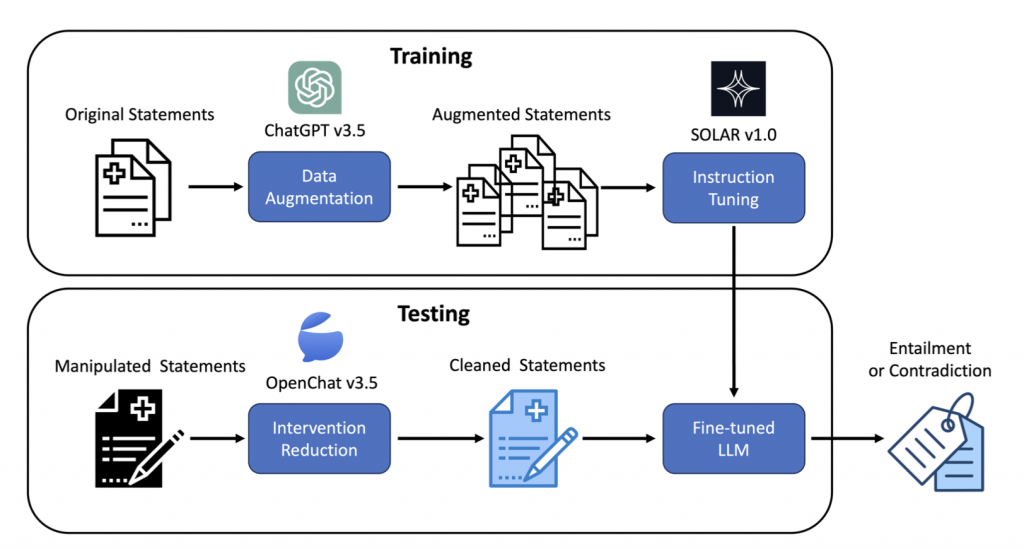
This study describes the model design of the NYCU-NLP system for the SemEval- 2024 Task 2 that focuses on natural language inference for clinical trials. We aggregate several large language models to determine the inference relation (i.e., entailment or contradiction) between clinical trial reports and statements that may be manipulated with designed interventions to investigate the faithfulness and consistency of the developed models. First, we use ChatGPT v3.5 to augment original statements in training data and then fine-tune the SOLAR model with all augmented data. During the testing inference phase, we fine-tune the OpenChat model to reduce the influence of interventions and fed a cleaned statement into the fine-tuned SOLAR model for label prediction. Our submission produced a faithfulness score of 0.9236, ranking second of 32 participating teams, and ranked first for consistency with a score of 0.8092.